RADON TRANSFORM AND FAST CONVOLUTIONS
- Documentation:
- Ph.D. Dissertation (Cesar Carranza @ UNM): (url)
- Presentation (Cesar Carranza @ UNM): (pdf)
- SSIAI2014: FDPRT
- ICIP2014: SFDPRT core
- IEEETIP2016: iFDPRT, iSFDPRT core, SFDPRT system, iSFDPRT system
- IEEETIP2017: Radon-Based and SVD-LU-Based 2D Convolutions
- MATLAB Implementation: (FDPRT, iFDPRT, Convolutions): (MATLAB code).
The following MATLAB scripts are provided under the GPL license.
- FDPRT, iFDPRT.
- Fast Radon-based convolution.
- Fast SVD-LU-based convolution.
- Hardware implementations (Passwords available upon request):
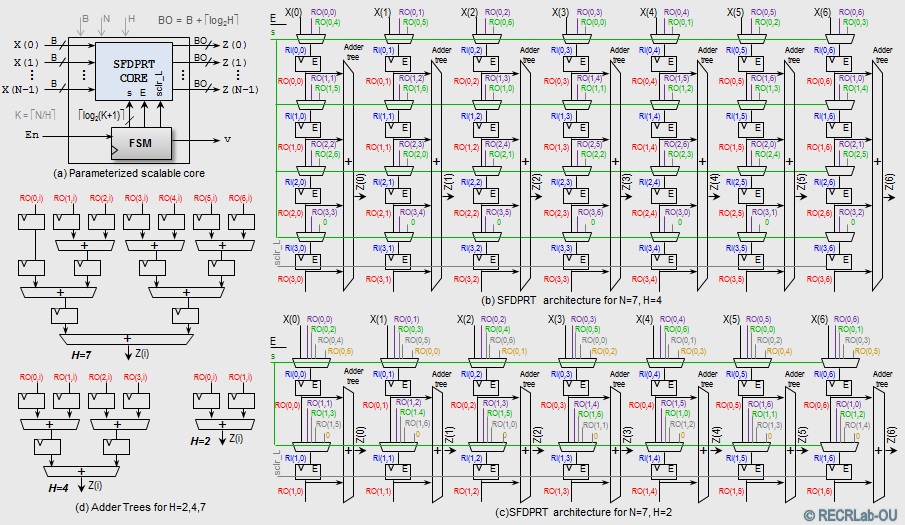
- Radon Transform: FDPRT, SFDPRT, iFDPRT, iSFDPRT
- Fast 2D Convolutions: Fast Radon-Based Convolution (FastScaleConv) and Fast SVD-LU-based Convolution (FastRankConv)
Radon Transform Hardware:
The following VHDL IP cores are provided under the GPL license.
|
|

|
|
|
|
|
|
|
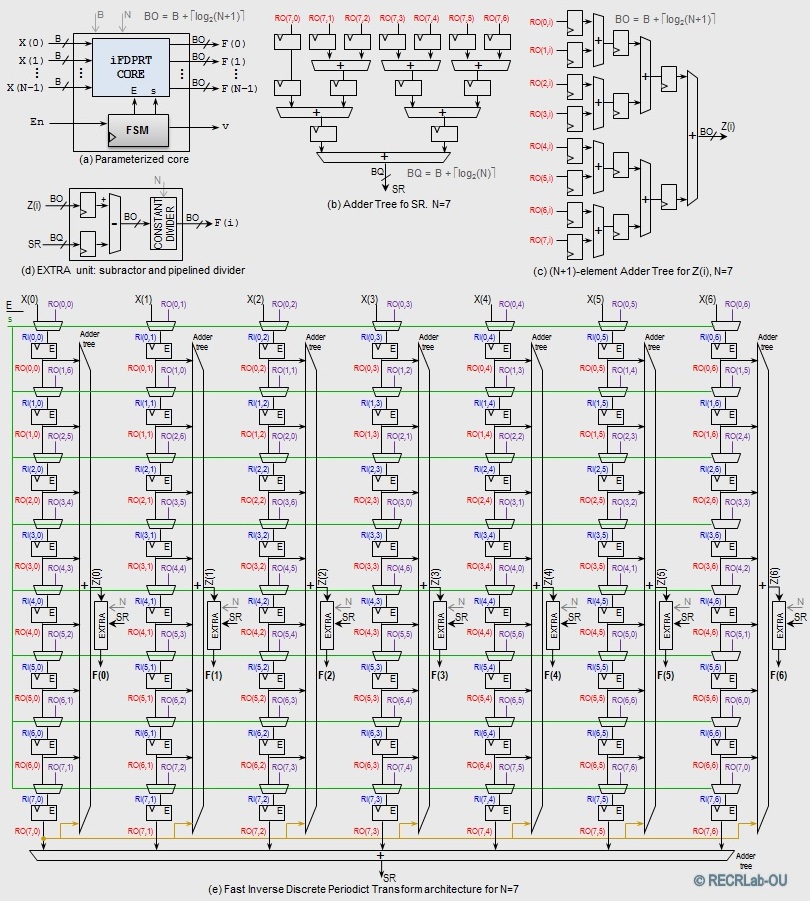
- iFDPRT: Fast Inverse Discrete Periodic Radon Transform (For Primes)
- Generic VHDL implementation: (Source Code)
- IEEETIP2016 paper: "Fast and Scalable Computation of the Forward and Inverse Discrete Periodic Radon Transform" (url)
|
|
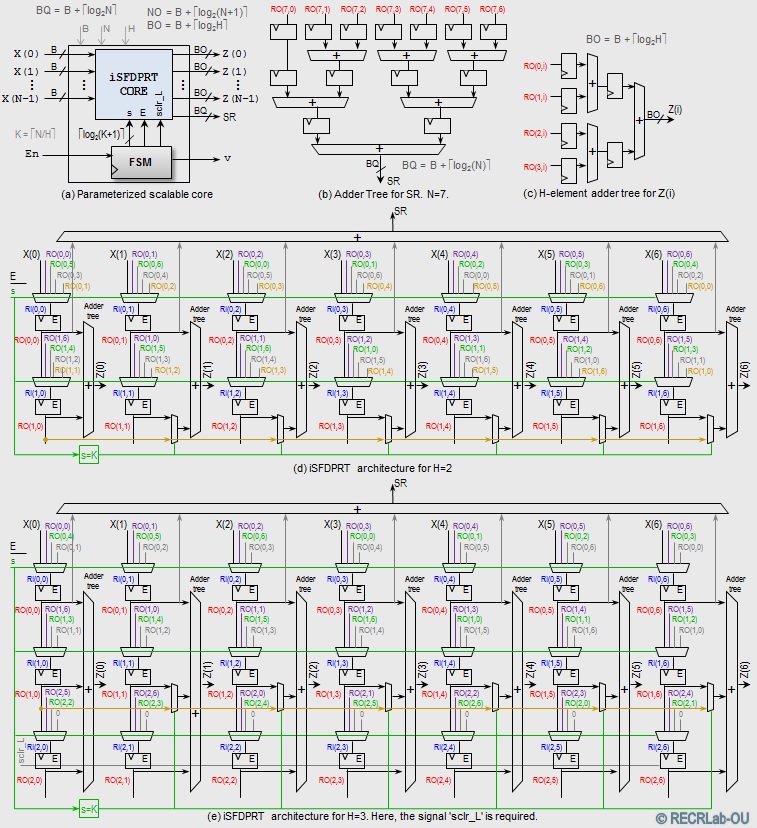
- iSFPDRT core: Scalable iFDPRT (For Primes)
- iSFDPRT core (Stand-Alone IP).
Generic VHDL implementation: (Source Code)
- IEEETIP2016 paper: "Fast and Scalable Computation of the Forward and Inverse Discrete Periodic Radon Transform" (url)
|
|
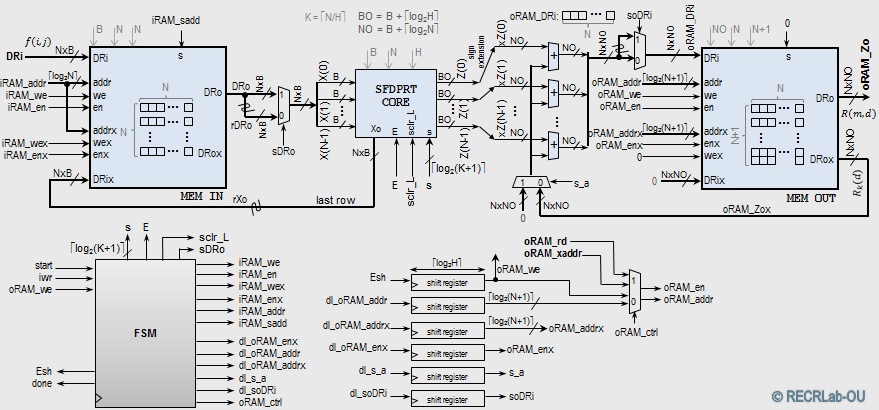
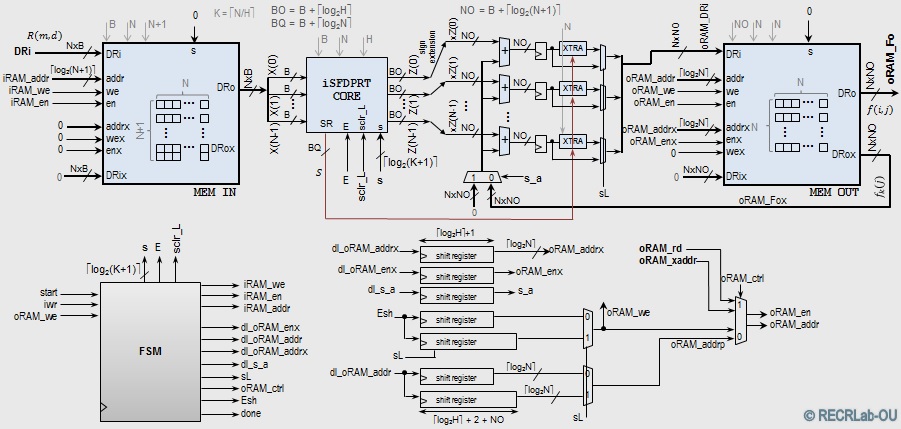
- iSFPDRT system: Includes the iSFDPRT core, memories, and ancillary circuitry.
- Generic VHDL implementation: (Source Code)
The code works for the 7-series Xilinx FPGAs/PSoCs (Artix-7, Kintex-7, Virtex-7, Zynq-SoC). It uses BRAM primitives RAMB18E1, RAM36E1.
- IEEETIP2016 paper: "Fast and Scalable Computation of the Forward and Inverse Discrete Periodic Radon Transform" (url)
|
|
Fast 2D Convolution Hardware:
- Documentation: IEEETIP2017 paper: "Fast 2D Convolutions and Cross-Correlations using Scalable Architectures" (url)
- The following VHDL IP cores are provided under the GPL license.
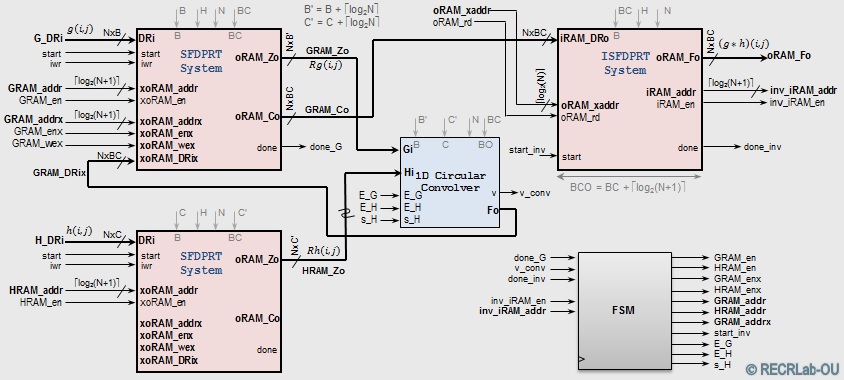
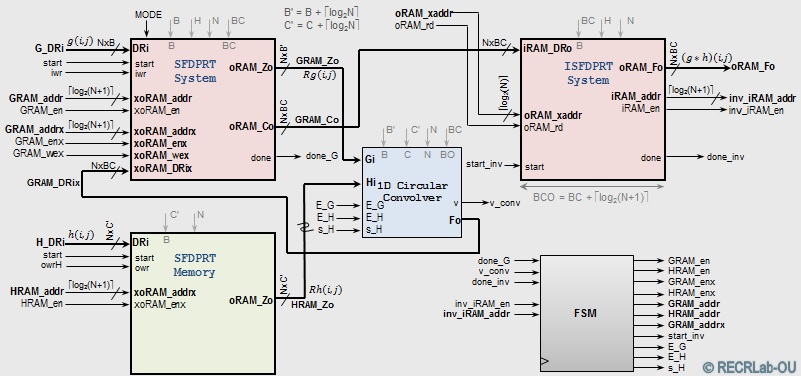
FastScaleConv: Radon-based 2D Linear Convolution. This requires modifying of the SFDPRT and iSFPRT systems.
- Memories: We allow up to 64 bits per pixel in order to store the convolution results
- SFDPRT system: Must allow the storage of the convolution result in MEM_OUT
- iSFDPRT system: MEM_IN memory is not included, as data comes from the SFDPRT system
- Two systems provided:
- FastScaleConv with no pre-computed kernel: The Radon Transform of the kernel is computed.
- FastScaleConv with pre-computed kernel: The Radon Transform of the kernel is provided in a memory.
- FastScaleConv with no pre-computed kernel. Generic VHDL implementation: (Source Code)
|
|
- FastScaleConv with pre-computed kernel. Generic VHDL implementation: (Source Code)
|
|
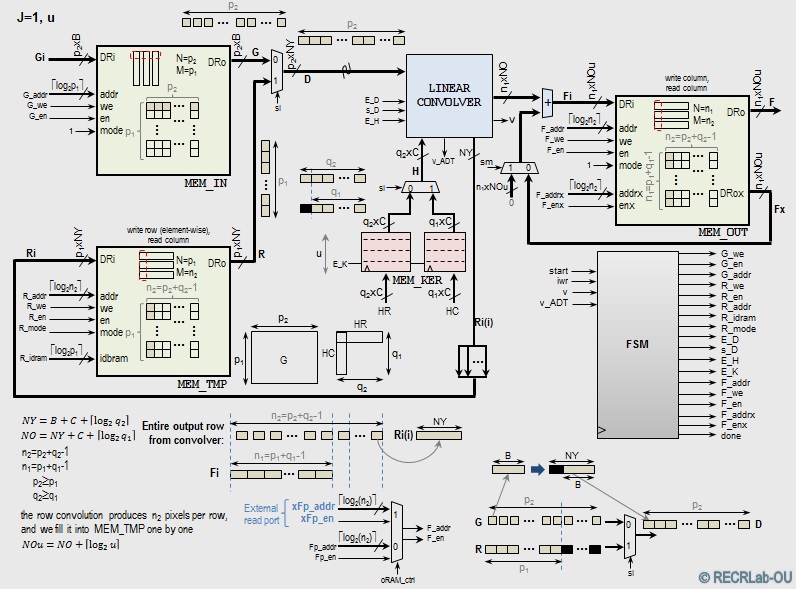
FastRankConv: SVD-LU-based 2D Linear Convolution
- FastRankConv. Generic VHDL implementation: (Source Code)
|
|
Reconfigurable Computing Research Laboratory (RECRLab), Electrical and Computer Engineering Department,
Oakland University